2023 iThome 鐵人賽
分享至
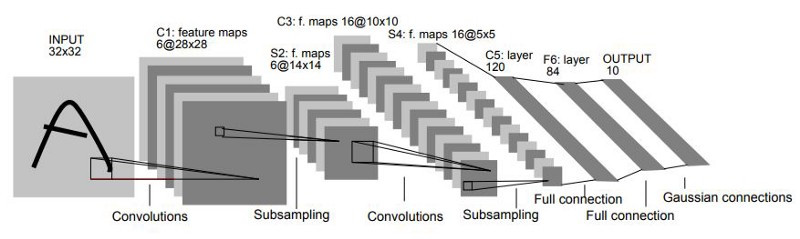
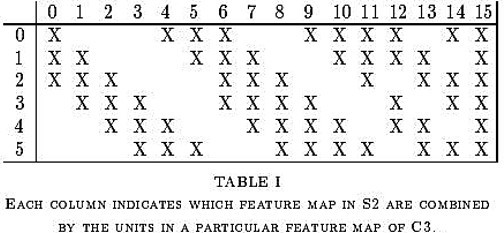
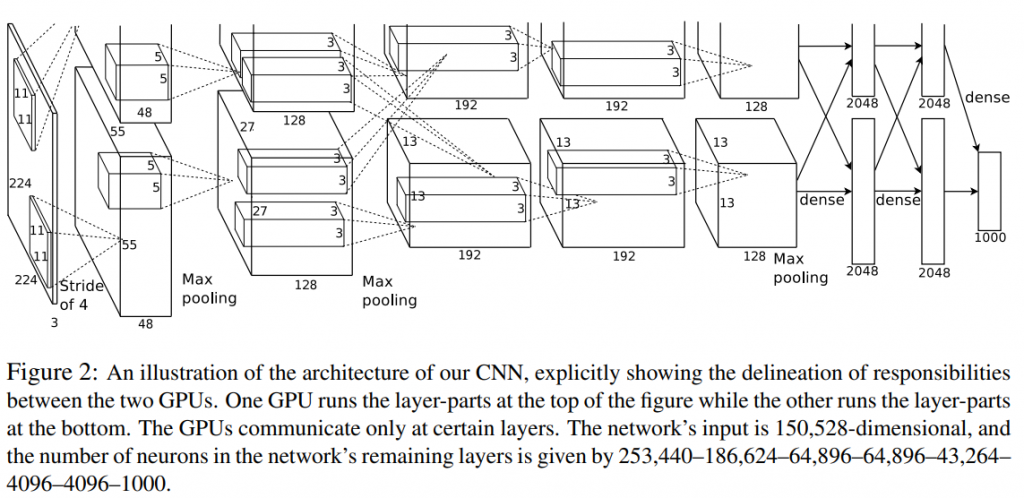
在之前的系列中,我們從最基礎的AI模型架構以及AI怎麼學習,一路討論到在影像任務中佔據霸主地位許多年的CNN架構。接下來的系列我們會著重在經典CNN架構論文的導讀與實戰,看看CNN架構的模型會遇到哪些問題,各位厲害的前輩們又是透過甚麼方式處理問題的。
IT邦幫忙


 iThome鐵人賽
iThome鐵人賽